Bulk import with dry-run preview
Upload a file, auto-map columns, validate every row, preview a zero-write dry-run — then commit, deduplicate, audit, and notify.
The whole flow, end to end
- Dry-run is the commit, minus the writes. The same pure
applyColumnMap → validate → naturalKey + contentHashpath renders the preview — what you see is exactly what lands. - Spoofed and oversize files die at the door. Size, MIME allow-list, and a magic-byte check (first 12 bytes) run before a single row is parsed.
- Idempotent by construction. naturalKey + contentHash dedup means re-importing the same file is always a safe no-op.
Mail = email sent
Bell = in-app alert
Amber diamond = automatic check
Amber card = blocked / rejected path
The dry-run and the commit call the SAME pure stageRows function — no side effects, no writes. Natural-key + content-hash dedup makes re-importing the same file a guaranteed no-op.
What the import guarantees
- Headers map to canonical fields with alias auto-suggest — a missed required column blocks the import, not corrupts it.
- Validation is row-indexed — every error names its row and field; nothing fails silently.
- Commit writes one immutable audit row with created + skipped counts; the result is emailed and shown in-app.
Live demo
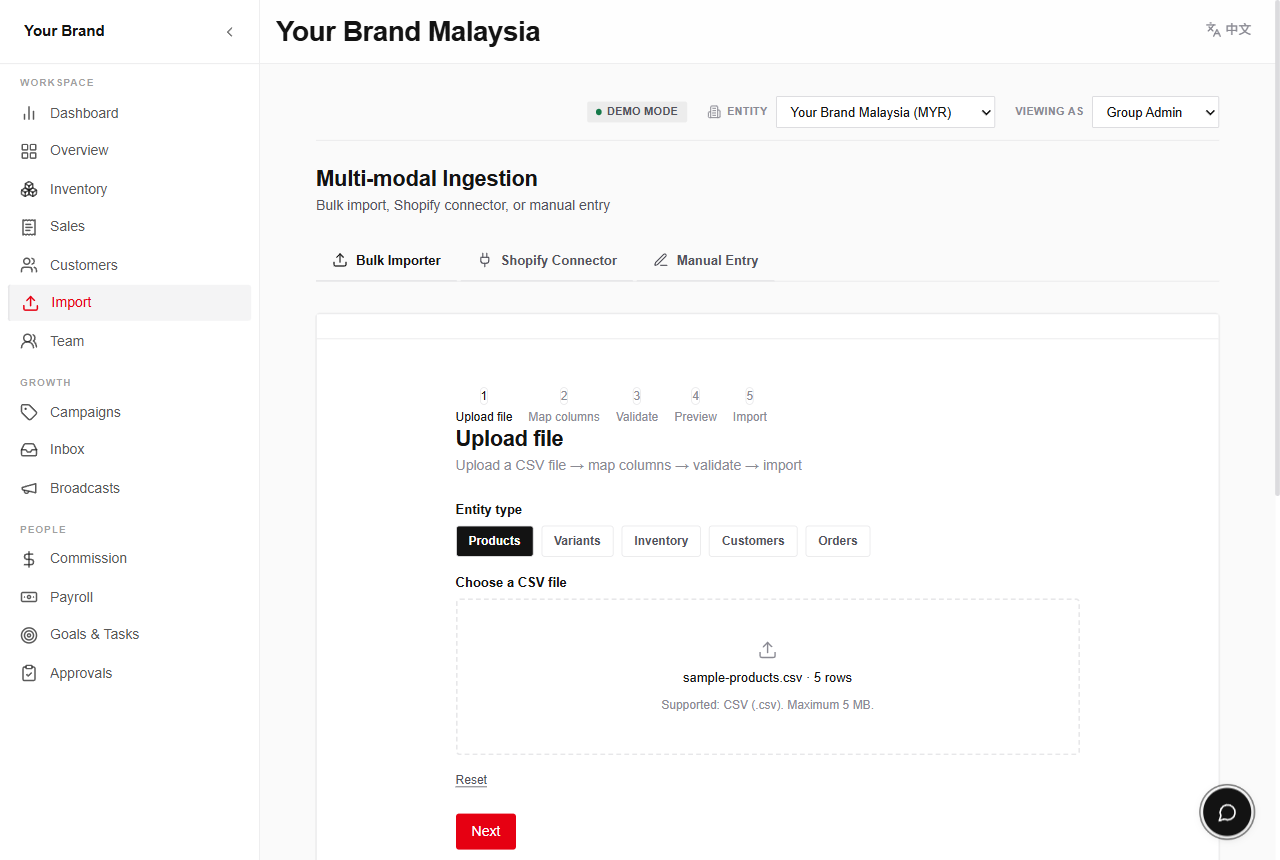
Recorded from the running app. Upload → auto-map headers → row-indexed validation → dry-run preview → commit — the same pure path the diagram describes.